多くのBiacore™ユーザーの皆様は、ka、kd測定のメソッド作成時にアナライト濃度条件設定の上記ルールを外れると出るアラートを見たことがあると思います。何故こんなルールがあるのでしょう。無視しても大丈夫でしょうか?
そうです、この画面(Fig.1)です。英語で“should”と書いてあるので結構ちゃんとやらなければいけないのかな、と思ってしまいます。実際、基本的には守ることを推奨するルールです。でも何故こんなルールがあって、どういうときに無視しても大丈夫そうかが理解の上、ご自身の求める目的を達成するデータ品質を十分担保できそうだと判断できれば無視しても構わないものです。逆にその理解なしで形式だけルールを守っても十分な品質のデータが得られないことだって考えられます。
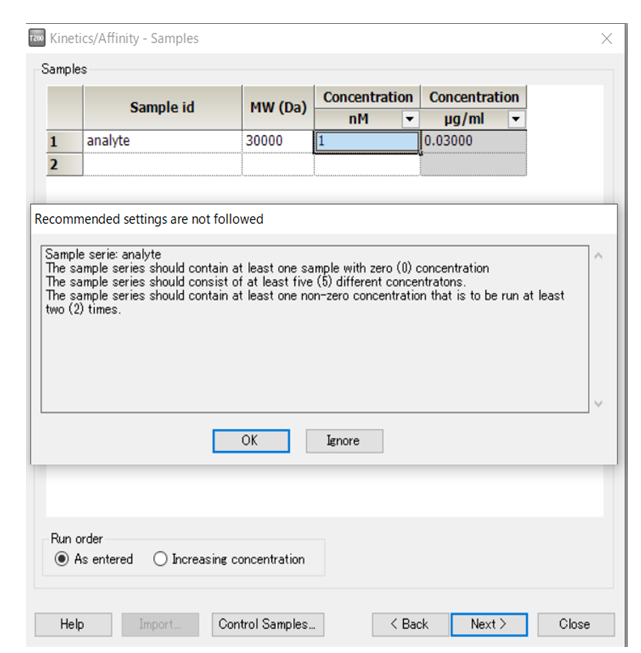
Fig.1
5 濃度の意味
実は1濃度だけの測定でもka、kd(そしてもちろんKDも)を求めることはできます。しかし、それだと本当に信頼性のある数値が得られているかを担保できているかという観点において必ずしも十分とは言えません。今回もBiacore™ Simul8™を用いて考えてみたいと思います。
例えば81, 27, 9, 3, 1 (nM)の5濃度のアナライトを添加したセンサーグラムを見てみたいと思います(Fig. 2)。これは大変理想的な濃度の振り方です。
まず基本的なお話しですが、相互作用のKD値はアナライトをどんな濃度を添加したとしても、同一です。KD値というのは観察している2分子が持つ固有の値だからです。しかし実測定では必ず大なり小なり各濃度のセンサーグラムに実験誤差が生じます。ここでもしある1濃度だけのセンサーグラムデータで解析を行った場合、そしてその濃度に特異的な誤差が存在する場合、解析値の真値からのずれが生じるということになります。
このような各濃度のセンサーグラムに存在する誤差は濃度間で分散していると仮定すると、5濃度のセンサーグラムに対してGlobal fittingをすることでより確からしい解析値が得られるだろうという考え方です。
一方で、よくあるケースとしては、アナライトを高濃度に添加したときに明らかに非特異的結合が現れるときがあります。つまり高濃度帯のセンサーグラムは明らかに観察したい特異的結合(真値)に対してずれがあると思われるときがあります。
このような場合高濃度帯のセンサーグラムを解析対象から外す、1希釈段階低濃度側の濃度シリーズを採用する、加えてもしアナライトの分子量とリガンドの活性率からRmaxを計算できるようなら、算出されたRmaxを固定値(constant)として入力してFitting計算を行う、等の対処をしたほうがいいかもしれません。
どのような判断基準でそのような2次的解析手法に転換するかは、統一的なものはありませんが、例えば濃度別のLocal fittingをしたときに高濃度帯だけ明らかに外れ値(ka、kd)の解になる、ですとか、そのようなケースの多くはフィッティングがきれいにかからなくなると思いますので、Chi2の大きさやChi2/Rmaxなどの指標を使用するのも一案かと思います。
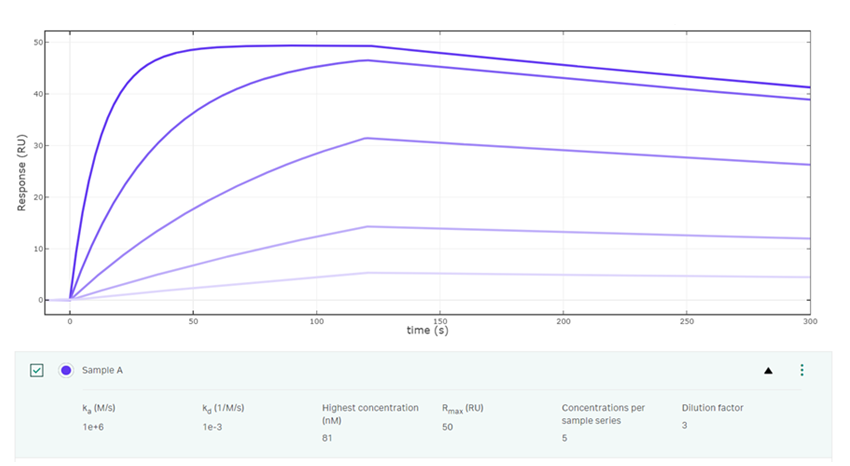
Fig.2
すこし脇道にそれたので、高濃度帯の非特異的結合のような話は無いとして、濃度数を減らすとしたらどのような濃度が良いか、という話に戻りたいと思います。
極端な話、濃度数を1したとした場合(これは実は抗体のKinetics screenなどで実際によく行われます。スクリーニングで選出されたものに関してはその後濃度を振って行うことも多いのですが、Roche社のデータが紹介されている弊社のアプリケーションノートでは両ka、kd値に大きな違いはないことが多いということが確認されているものもあります。)、どの1濃度にするのが適切でしょうか。
答えを言いますと、最高濃度の81nMや1nMは避けて、真ん中あたりの濃度を使うのが良いということになります。Fig.3をご覧ください。ここではFig.2 のセンサーグラムを濃度別に分けて(青色)、それぞれのセンサーグラムに対して、ka値を2倍にしたもの(赤色)、kd値を1/2倍にしたもの(水色)、Rmax(黒色)で表記しています。
言い換えますと真値である青色のセンサーグラムに対して、赤色と水色のセンサーグラムはka値の誤差が1/2から2倍あった時のセンサーグラムが形状変化する範囲を意味しています。81nM、1nMの時にはその形状変化の範囲がやや狭くなっています。さらに1nMの時は結合相におけるセンサーグラムが直線的です。このことはこの図で示している1/2~2倍の誤差範囲においてさらに大きな誤差を生む可能性があります(マストランスポートリミテーションの存在が関係しますが、今回はその説明は割愛します。)。
またセンサーグラム自体がRmaxよりかなり下に位置します。このことはka、kdとともに解析パラメーターであるRmax値の誤差を大きくしがちで、連動してka、kdの誤差を大きくしがちになります。従いまして、どれか1濃度だけ解析誤差のリスクが小さいと予想されるものを選ぶとしたら、27nMかそこより少し低濃度側くらいが良いのではないか、ということになります。このようにBiacore™ Simul8™を用いて、予想されるka、kd値の範囲内でどのくらいの濃度帯を選べば良いのか、ということを考察することが可能になります。
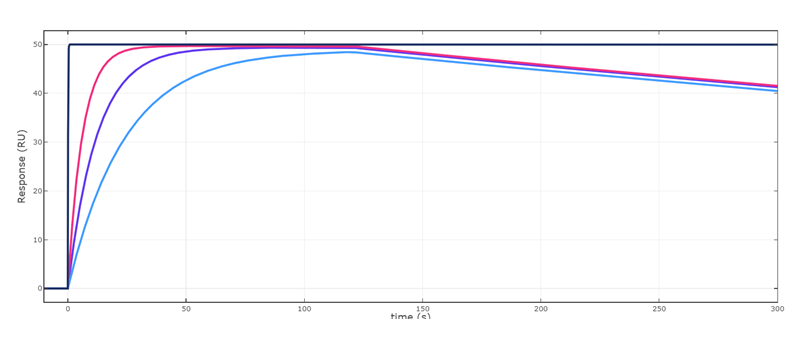
Fig.3-1 81nM
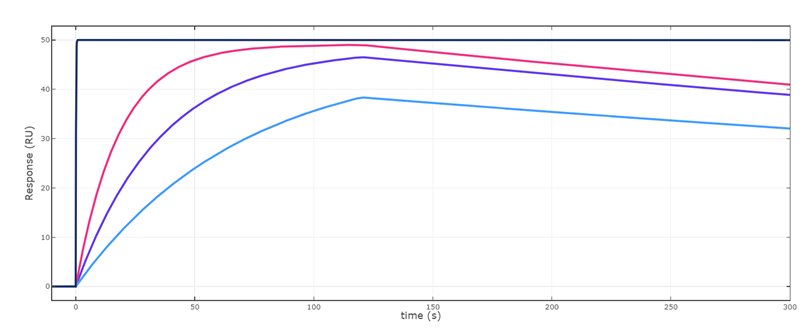
Fig.3-2 27nM
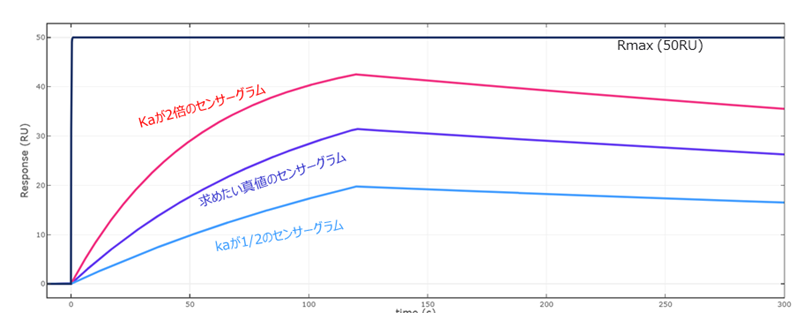
Fig.3-3 9nM
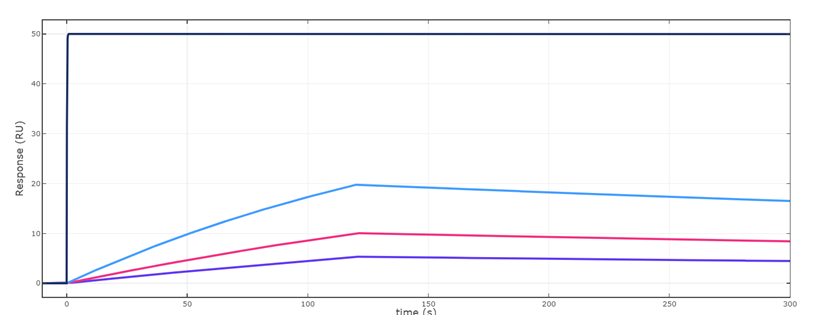
Fig.3-4 1nM
0 濃度の意味
0濃度の意味は、アナライト側のブランクサンプルという意味になり、これに関しては2000年代初頭くらいまではあまり設定しないこともあったのですが、近年は必ず設定することが勧められます。
これはBiacore™のKinetics測定は(前回の当メールマガジンでも言及しましたが)基本的に固定化量を下げることが望ましく、また近年の装置の高感度化に伴い、観測レスポンスレンジが小さくなったことによります。このような小さなレスポンス帯ではわずかなベースラインドリフトや毎サイクル起こることがある小さなノイズや歪みなどを差し引くことで初めて、十分な信頼性のある相互作用データを取得できるからです。(Fig. 4)
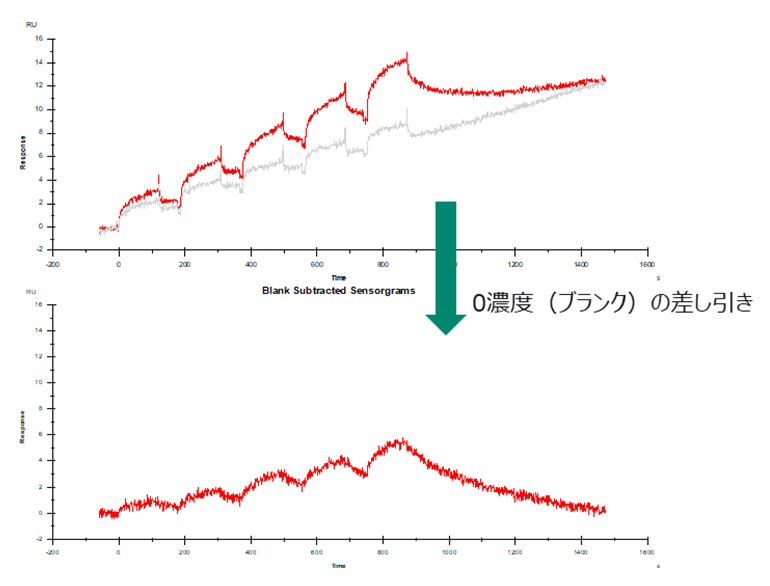
Fig.4
n=2 の意味
アナライト添加濃度中少なくとも1濃度に関しては n=2 で測定すること(マルチサイクルカイネティクスにおいて)が求められます。これも省略することはすべてのケースでお勧めできません。
そして意味をご理解するとどのような順番でn=2を設定するか、ということに関しても考慮に入れなければならないことに気づきます。
この n=2 の測定理由は、実際観測したデータを取得した測定系(システム)が十分正常であったかを簡易的に確認するためのものです。厳密な医薬品の品質管理の試験法などでは“システム適合性試験”というものが設定されて似たような概念の評価をしますが、これをずっと簡易的にしたような意味合いです。
従いましてこのn=2は測定系内の全てのサイクルが正常であることを確認するために本来サンプル添加サイクルの一番最初のサイクルと最後のサイクルにそれぞれ設定するのが理想です。
その結果十分に再現性のとれたセンサーグラムが取られた場合、おそらく固定化したリガンドやアナライトも経時的に失活していないし、従ってその間のサイクルのデータも信頼できる、という判断をすることができます。
もしn=2のサンプル無しでやった場合、もし経時的な失活などの変化を含んだデータで出した数値を分からず採用してしまったら。。。
ちょっと怖いですよね。
最後に、もしよろしければ、Cytiva Webinarをぜひご覧ください。”Biacore™の測定系構築の勘所” などでも添加濃度などについて語られていますが、合わせてご覧になりますとご参考になるかもしれません。